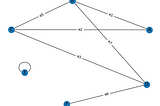
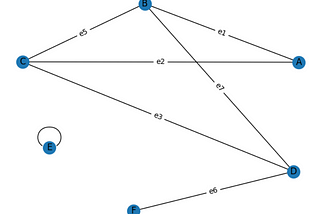
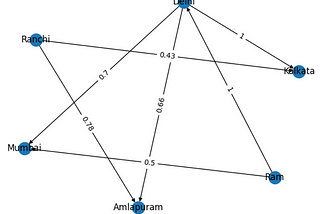
Shubham SaketinGeek CultureGraph or Networks — Chapter 4Finding number of graph components with Depth First Search2 min read·May 21, 2022----
Shubham SaketinGeek CultureGraph or Networks — Depth First Search AlgorithmChapter 34 min read·May 16, 2022----
Shubham SaketinGeek CultureGraphs or Networks — Chapter 1Learn efficiently3 min read·Apr 24, 2022--1--1